
Tous les Agents IA d'entreprise
ont besoin d'un Control Plane
Expérimentation, observabilité, guardrails et gouvernance — pour vos Agents IA composites, en production, sur chaque appel LLM.
Compatible avec les stacks IA que vos équipes utilisent déjà
Visibilité, contexte et contrôle pour l'entreprise
Visibilité de bout en bout
Traçabilité complète sur toute la hiérarchie agentique. Suivez chaque application IA sur tout son cycle de vie.
Explorer l'observabilité agentiqueAnalyse de cause racine
Comprenez les comportements des agents et remontez à la racine avec le contexte d'exécution et la lignée des décisions.
Voir l'analyse root-causeGouvernance & policies
Appliquez vos politiques via guardrails inline. Maîtrisez votre TCO avec les modèles de contrôle intégrés.
Réduire vos coûts d'évaluationLe seul enforcement inline sur le chemin requête/réponse de vos agents
Sorties garanties
Les modèles ne traitent que les entrées approuvées ; vos développeurs ne reçoivent que des sorties approuvées.
Un seul control plane
Passez par la gateway que vous utilisez déjà — LiteLLM, Agentgateway ou native TokenSaver.
Intelligence de flotte
Une vue unifiée sur chaque développeur, chaque token, chaque euro consommé.
Capacités de la plateforme TokenSaver
Le cockpit de gouvernance
Reprenez le contrôle
de vos agents IA.
La première plateforme qui sécurise, optimise et gouverne vos LLM en temps réel — sans jamais quitter votre périmètre.
Pipeline de gouvernance
Chaque appel LLM · orchestré · tracé · sécuriséLe cockpit en action
Passez du monitoring global à la trace détaillée de chaque pipeline IA : tool calls, agents MCP, cache, RAG et guardrails dans une seule interface.
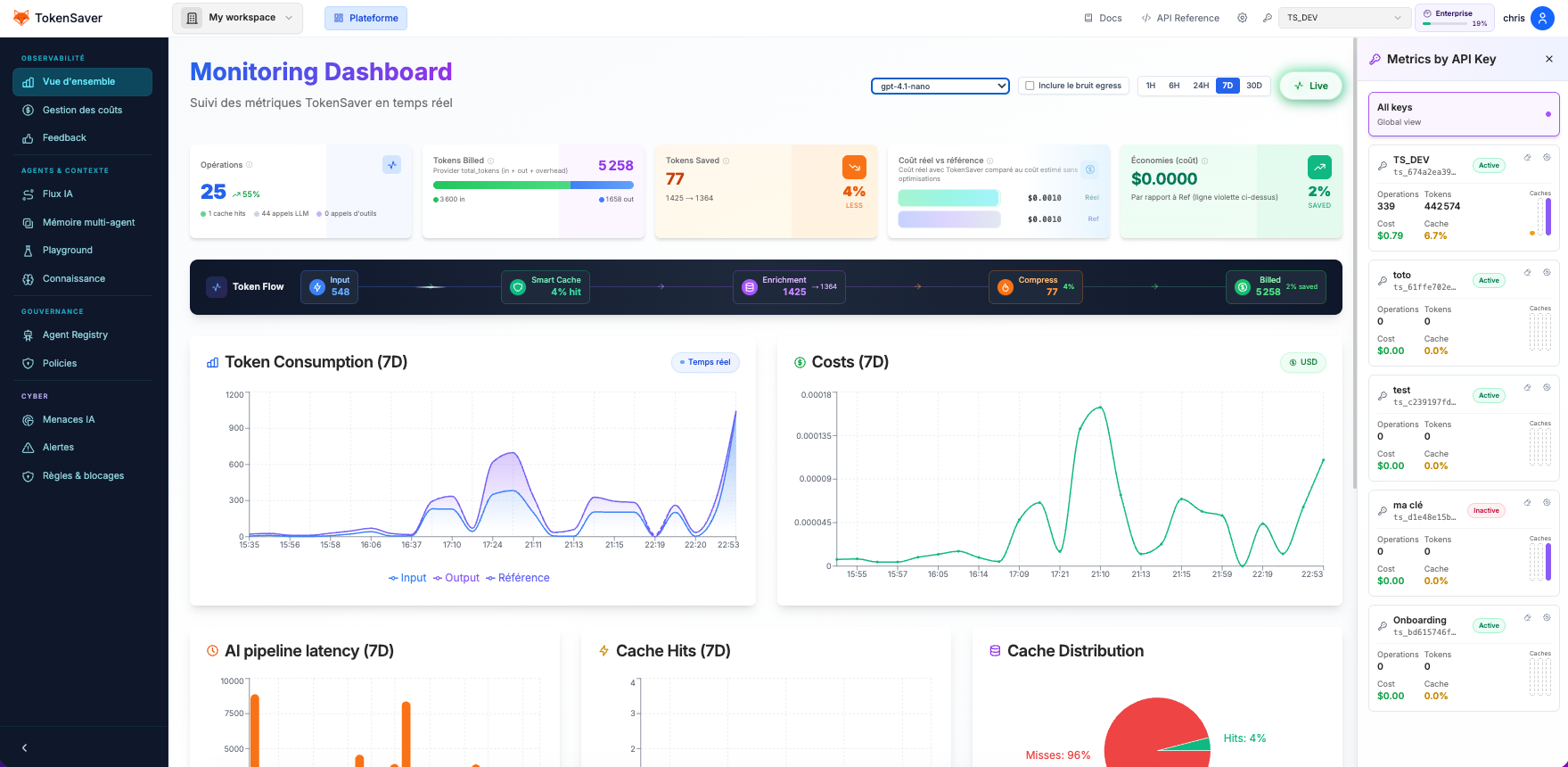
Observabilité temps réel
Suivez les tokens, les appels LLM, la latence et les caches sur chaque agent de votre flotte.
Trace de bout en bout
Visualisez chaque étape du pipeline : tool calls, cache, RAG, compression, PII et réponse finale.
Graphe d'agents & outils
Comprenez les interactions entre agents, outils MCP et modèles dans une timeline interactive.
Alertes & guardrails
Détectez les anomalies, bloquez les comportements à risque et auditez chaque décision.
Optimisez votre pipeline IA métier sans une ligne de code.
TokenSaver applique des méthodes scientifiques de sélection de modèles, de cache et de compression au cœur de vos flux métier. Vous gardez le contrôle des coûts, de la qualité et de la latence — tout en restant concentré sur votre valeur ajoutée.
Réduction des coûts LLM
En moyenne -45% de tokens sur le pipeline complet : cache sémantique, compression intelligente par type de contenu (jusqu'à -90% sur JSON & logs) et routage vers le modèle le plus efficace — sans toucher au code de vos agents.
Latence maîtrisée
Basculez automatiquement vers les endpoints les plus rapides, activez le streaming optimisé et gardez la qualité de réponse sous contrôle avec des seuils métier configurables.
FinOps IA d'entreprise
Budgets par projet, alertes de dépassement, allocation des coûts par équipe et traçabilité de chaque euro dépensé : maîtrisez votre TCO IA en temps réel.
Approche scientifique & innovante
TokenSaver intègre des techniques avancées inspirées des travaux de recherche de Microsoft et d'autres leaders — optimisation de prompts, sélection de modèles et fallback intelligent — directement dans le pipeline métier.
Vos agents lisent moins, et comprennent mieux.
TokenSaver détecte le type de chaque bloc de contexte — JSON, logs, RAG, code, diffs — et applique la stratégie de compression adaptée. Jusqu'à -90% de tokens, sans perdre l'information critique.
Les trois piliers TokenSaver
Sécurité, contexte métier et efficacité — sans compromis.
Votre base de connaissance
reste chez vous.
Enrichissez chaque prompt avec votre contexte métier — documents, bases internes, tickets — sans jamais quitter votre périmètre. Récupération vectorielle dans votre périmètre, contrôle d'accès par rôle.
Routage par type de contenu — JSON, logs, RAG, code, diffs. Compression réversible (CCR), rien n'est perdu.
PII, PHI & secrets filtrés avant chaque appel LLM.
Pourquoi TokenSaver
Livrez plus vite. Protégez du risque. Maximisez le ROI.
Monitoring continu et gouvernance auditable — bien au-delà d'une évaluation passive ou d'un stack open-source assemblé à la main.
Pipeline unifié
Cache sémantique, RAG, compression et PII dans un pipeline prévisible en amont de chaque modèle.
Compatible OpenAI & Anthropic
Vos clients existants — Claude Code, LangChain, n8n, LibreChat — passent par la même clé Bearer.
SDK & API natives
SDK Python open-source, API OpenAI-compatible, ou API native POST /pipelines/run.
Ce que TokenSaver change concrètement dans votre organisation.
Trois cas d'usage phares pour comprendre l'impact du pipeline gouverné.
Gouvernance IA sans ligne de code
Connectez vos applications métier IA existantes — LangChain, LangGraph, CrewAI, n8n, Make, Zapier, Open WebUI, LibreChat — via une API OpenAI/Anthropic-compatible. Le pipeline gouverné s'intercale automatiquement, sans modifier le code de vos agents.
Anonymisation temps réel des données sensibles
Détection et rédaction PII, secrets et données métier sensibles avant tout envoi au fournisseur LLM. Rien ne sort de votre périmètre : les données sensibles restent chez vous, les modèles ne voient que le strict nécessaire.
Contrôle des coûts et quotas par département
Fixez des budgets et des quotas par business unit, équipe ou utilisateur. Recevez des alertes avant dépassement, coupez proprement au seuil, et refacturez les coûts IA à l'usage réel de chaque département.

TokenSaver est membre de La French Tech Aix-Marseille
Rejoindre La French Tech Aix-Marseille, c'est l'engagement d'une innovation ouverte, responsable et ancrée dans l'écosystème du Sud-Est. Nous le traduisons chaque jour par une gouvernance IA souveraine, transparente et au service des équipes européennes.
En savoir plus sur La French Tech Aix-MarseilleConstruisons ensemble la gouvernance IA de votre entreprise
Nous sélectionnons chaque mois quelques équipes IA pour un accompagnement direct : démo personnalisée, POC gouverné en 30 jours, tarifs Early Adopter et accès prioritaire aux nouveaux modules.