Catalogue-backed calls
Every provider and model pair is checked against the same live catalogue the console uses — no shadow lists or one-off client configs.
Platform
Integrations, agent tracing, catalogue governance, SDK, architecture, and use cases — for teams that need depth beyond the homepage.
Agentic AI observability
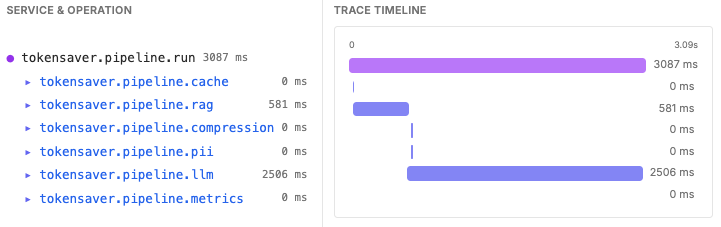
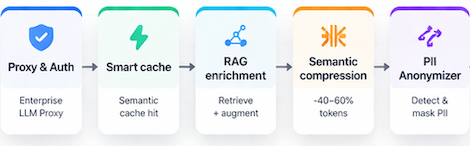
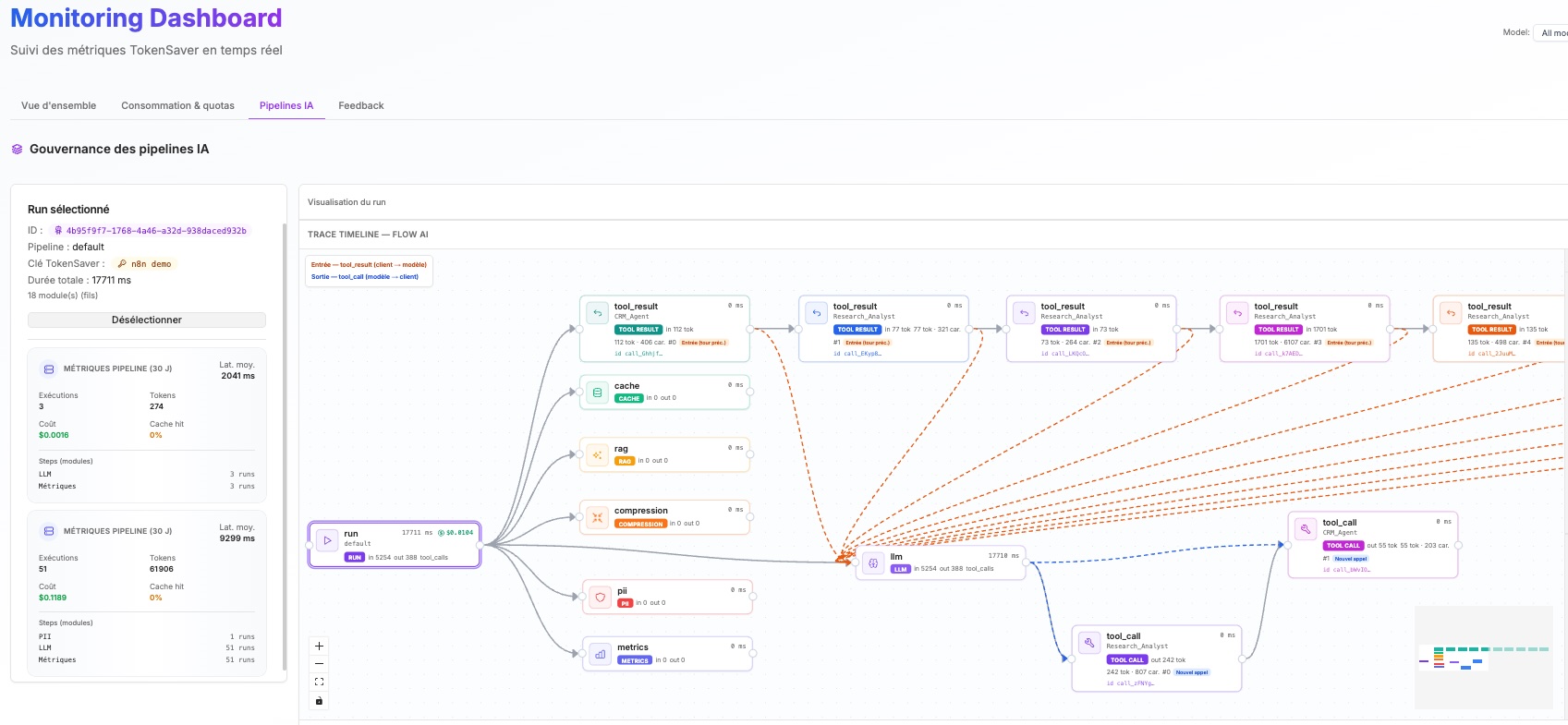
From a single prompt to multi-step agents calling tools — and agents delegating to other agents — TokenSaver secures and records every exchange. See the full run graph: cache, RAG, compression, PII, LLM calls, and tool results in one trace timeline, with cost, latency, and policy outcomes per step.
Works with your stack
Unified control plane
TokenSaver sits in front of your vendor APIs: the same policies, catalogue, metering, and pipeline run whether traffic comes from the console, an OpenAI-compatible client, or the native API — so models stay under control as you add providers and scale usage.
Every provider and model pair is checked against the same live catalogue the console uses — no shadow lists or one-off client configs.

Workspace keys, quotas, and spend views anchor on TokenSaver — vendor credentials stay on the platform while teams keep a single place to enforce access and budgets.

Semantic cache, retrieval, compression, and PII controls run in a fixed order before the upstream model — so optimization and safety don't depend on which provider answers the call.

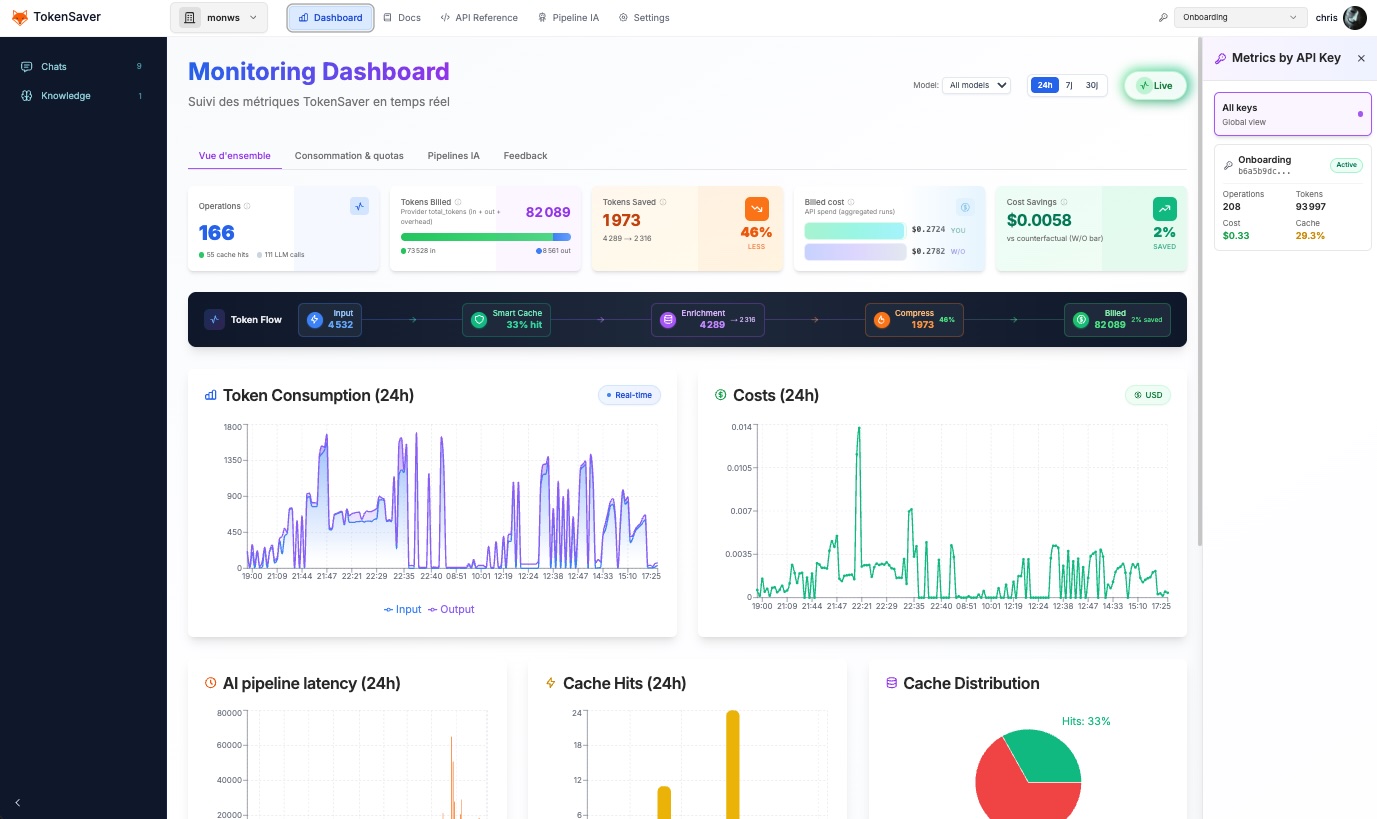
Traces and metrics across pipeline steps give platform and security teams visibility into cost, latency, and policy outcomes — not just raw model output.
Explore the public model catalogue or call GET /api/v1/llm-reference/models for the authoritative list for your environment.
How you connect
Whether your teams live in chat UIs, IDEs, or custom backends, you land on the same TokenSaver path: cache, RAG, compression, PII, then the model — with org-scoped keys, quotas, and dashboards. Pick the surface that matches your stack; no duplicate policy layers.
The platform reference catalog spans 7+ providers (OpenAI, Anthropic, Google Gemini, Mistral, Grok, DeepSeek) and 261+ LLM models (chat and embeddings). Same model / provider pairs the native and OpenAI-compatible APIs validate against GET /api/v1/llm-reference/models.
https://api.tokensaver.fr/openai/v1Chat Completions, Responses API, models (all routed providers), embeddingshttps://api.tokensaver.fr/api/v1Pipelines, RAG, chats — Python SDK & custom appsNo-code · Chat tools
Connect LibreChat, Open WebUI, and other tools that accept a custom OpenAI base URL. Set base URL to …/openai/v1, use your TokenSaver API key as Bearer, and optional X-Tokensaver-* headers to tune cache, RAG, compression, and PII per request, or X-Tokensaver-Apply-Key-Pipeline-Defaults to reuse pipeline defaults saved on the API key — no fork of your client required.
Console · Teams
The hosted app for operators and builders: governed chat, dashboard and spend views, model pricing, API keys, pipeline defaults, and in-product docs. Ideal when you want clicks, not config files — still the same pipeline the APIs run.
Open the consoleDevelopers · Code
POST /api/v1/pipelines/run, typed tokensaver-sdk on PyPI, and the same reference your workspace shows after sign-in. Pick any catalog-backed provider/model pair — 261+ LLM models across 7+ vendors in the reference catalog. Best when you need fine-grained requests, agents, or CI — governance and metering match the console and OpenAI-compatible traffic.
Same governance, optimization, and security layer in front of OpenAI, Anthropic, Google Gemini, Mistral, Grok, DeepSeek, and more — route and compare 261+ catalog models without duplicating policies or losing cost visibility.
Built for the move from pilot to production: one control plane as usage, providers, and internal stakeholders grow.
Platform
Four capabilities that work together — not a pile of disconnected APIs. Configure once, override per request when you need to.
Product teams get business value fast; platform and security teams keep governance, spend control, and reliability as adoption scales.
A single workspace to tune cache thresholds, RAG depth, compression level, and PII policies — aligned with what the API actually runs.
Learn moreInstrument LLM traffic with OpenTelemetry-friendly traces and metrics across every pipeline step. Expose the same signals to Prometheus and Grafana for alerting, SLOs, and cost or latency dashboards your platform team already runs.
Learn moreIngest PDFs and retrieve grounded chunks with multimodal-ready storage — context that stays scoped to the right user and workspace.
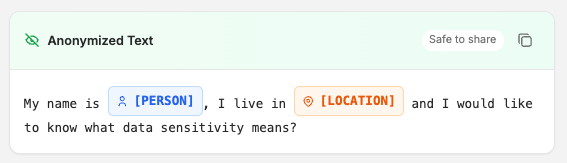
Learn moreData sensitivity by design: automatic PII detection and configurable anonymization or redaction on every exchange, so regulated or personal content is stripped before it reaches model APIs. Harden data flows against accidental leakage to LLMs and downstream logs while you scale usage with confidence.
Learn moreIntelligent routing
Every call flows through the same modules — so you optimize tokens, enforce guardrails, and keep audits simple. Swap providers without losing cost signals or safety posture.
Get free accessLifecycle tools
Test overrides, inspect per-step metrics, and correlate runs with traces — low-friction operations for platform teams and app owners alike.
See use casesArchitecture
Embed anywhere your apps run — console, OpenAI-compatible clients, or native API / SDK — supervise usage centrally, enforce org boundaries, and keep provider keys off end-user devices.
Custom apps and agents use the native API; LibreChat, Open WebUI, and similar tools use the OpenAI-compatible base path — one product behind both.
Developers · Open source
tokensaver-sdk is open source (MIT) and free for the open-source community, published on PyPI. TokenSaver builds on LangChain and LangGraph to run governed LLM pipelines and adds a governance overlay on top — access control, budgets, semantic cache, RAG, compression, PII policies, and observability. The SDK is the HTTP client to that stack: same behaviour and limits as the console, whether you trigger runs from code or the UI.
Orchestration inside the platform leans on LangChain / LangGraph patterns; TokenSaver enforces policy and cost before traffic reaches commercial model APIs.
Use cases
Same pipeline, different jobs — customer-facing or internal.
Grounded answers with RAG, redacted transcripts with PII policies, and cache for repeat intents.
Benefit: Lower cost per ticket, faster replies.
Central keys, workspace isolation, and spend visibility across teams — without shadow IT keys.
Benefit: Governance without blocking builders.
Long-context compression before the model call, retrieval over your knowledge base, full run history.
Benefit: Deeper context, controlled spend.
Trace IDs, token and cost breakdowns, export-friendly metrics for FinOps and security reviews.
Benefit: One source of truth for LLM spend.
Trust
Guardrails and visibility that stay aligned as you scale traffic.
Fixed module order, plan-aware feature flags, and configurable PII strategies — reduce drift between environments.
Org-scoped provider keys, user-scoped cache and retrieval, and masking before payloads leave your policy boundary.
Per-run steps, cache hit types, RAG attribution hooks, and OTel — so incidents are short and audits are boring.
Getting started
Register OpenAI, Anthropic, Google, or Mistral keys at org level. Applications call TokenSaver only, so provider credentials stay off app servers and client devices.
Outcome: one secure gateway for all teams and environments.
Define governed defaults for semantic cache, RAG, compression, and PII controls. Keep safe per-request overrides for advanced cases, without losing consistency.
Outcome: lower token cost, predictable behavior, faster delivery.
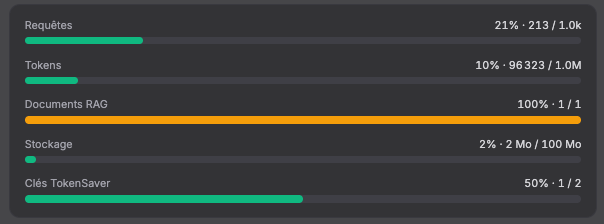
Track usage, spend, cache hit types, and step-by-step traces in one place. Detect anomalies quickly and provide audit-ready visibility for platform, security, and finance teams.
Outcome: confident rollout across products, teams, and providers.
A single API and policy layer in front of multiple model providers. Your applications call TokenSaver; TokenSaver applies cache, retrieval, compression, and safety, then calls the right model with your org's keys.
Yes. Configure the client's OpenAI base URL to point at TokenSaver's OpenAI-compatible path (…/openai/v1), and authenticate with your TokenSaver API key. The same governed pipeline runs as for the console and the native API; optional X-Tokensaver-* headers adjust cache, RAG, compression, and PII per request. Code examples: OpenAI-compatible docs.
TokenSaver runs an ordered pipeline: semantic cache, retrieval on your local RAG, compression of injected context, then sensitive-data detection and anonymization (PII) before the LLM call. You cut billed tokens while controlling personal and confidential data sent to models. Same behavior via console, native API, or OpenAI-compatible path — with quotas and monitoring. See plans on Pricing.
The platform is designed for both cloud SaaS and self-managed deployments — keep data and keys inside your perimeter when required.
Runs record tokens, estimated cost, and cache outcomes so finance and engineering can reconcile usage without exporting raw logs.
Yes — cache, RAG, compression, PII, then LLM, then metrics. That predictability is what makes debugging and compliance reviews tractable.
Yes. tokensaver-sdk is open source (MIT), free to install from PyPI. It calls the TokenSaver HTTP API: the product uses LangChain and LangGraph as part of its pipeline implementation and layers governance (cache, RAG, compression, PII, quotas, observability) on those foundations — you integrate from Python without re-implementing that stack yourself.